Case Study
Building Figma’s First LLM QA Program
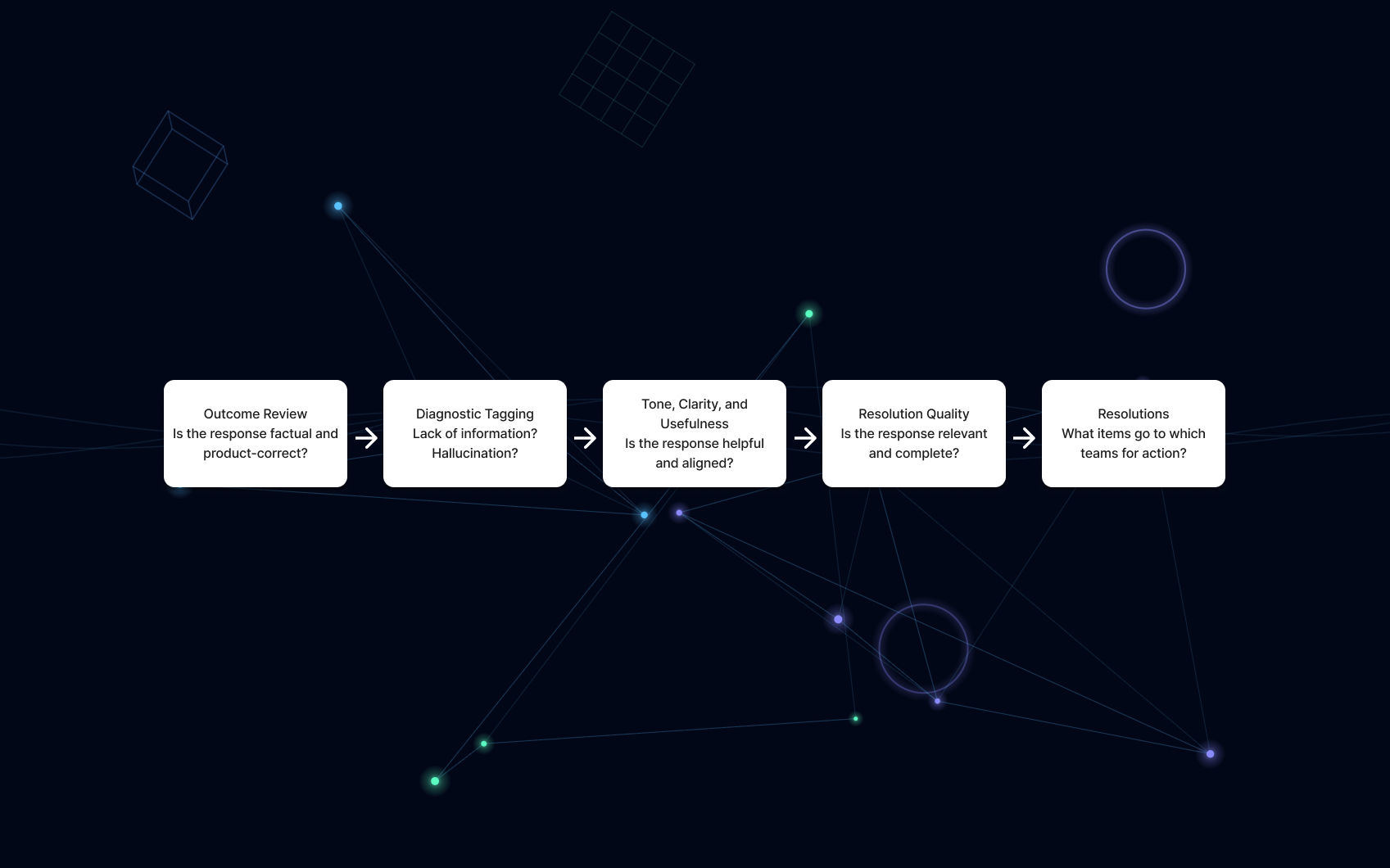
A system that detects model failures, protects customer trust, and teaches the organization how to evaluate AI with rigor.
Summary
Figma needed a consistent way to evaluate AI quality across Support. I built a structured QA program that identifies where a model succeeds, where it fails, and why. The system gave teams a shared language for diagnosing issues, measuring improvements, and guiding Engineering toward actionable fixes. The framework draws on systems I’d been developing long before Figma.
Problem
AI was becoming a core part of Figma’s support ecosystem, but there was no reliable way to measure or diagnose quality. Output varied, and teams didn’t have a shared framework for understanding what the model was doing or where it was failing.
Key gaps: • No shared quality rubric • No taxonomy for failure modes • No process for identifying regressions • No durable record of experiments • Specialists didn’t trust outputs • Engineering had no actionable feedback loop
Without a formal evaluation system, quality stayed anecdotal and unmeasurable. The team couldn’t measure performance, pinpoint issues, or provide Engineering with clear signals for improvement.
Approach
I began by mapping the different ways the model could fail. Errors weren’t uniform, so understanding failure types was the fastest way to see where the model needed support. I treated mistakes as a spectrum, from intent and grounding issues to reasoning gaps and policy drift.
I anchored the work around three questions: • Was the intent correct • Was the response grounded in the right information • Did the output align with product and policy expectations
With those patterns defined, I designed a workflow that evaluates responses through these layers in a consistent sequence. The goal wasn’t just to score correctness. It was to create a repeatable method that reveals why the model behaved a certain way and what the right team could act on next.
This replaced pass-fail scoring with a clearer picture of model behavior. Each stage feeds into the next, creating a profile that helps teams debug issues accurately instead of guessing where the problem lies.
The System I Built
This system creates a consistent, repeatable way to understand model behavior across layers, from intent to calibration.
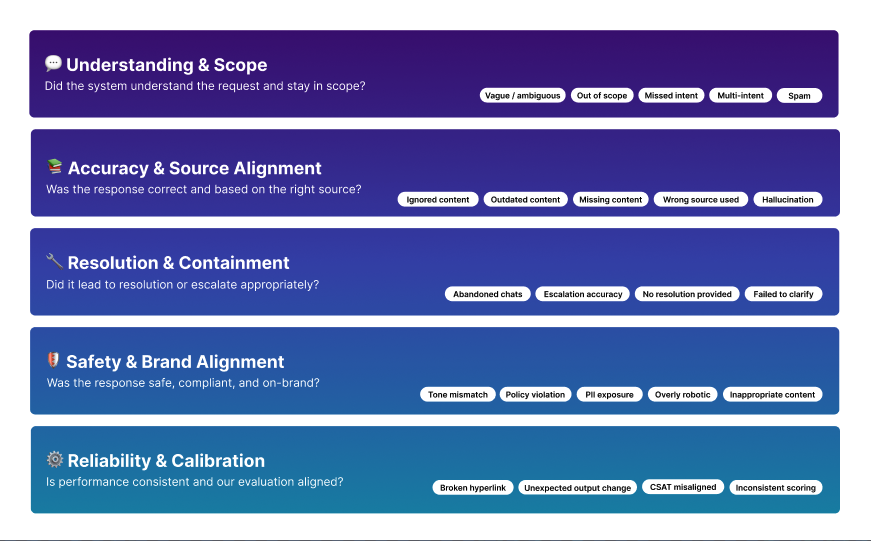
To replace anecdotal evaluation with measurable quality, I designed a modular LLM QA system that combined signals-based scoring, structured failure detection, and a repeatable human-in-the-loop workflow. Each component was built to scale across teams while reducing cognitive load for specialists and giving Engineering actionable feedback.
The QA Modules
These are the core modules that form the system’s architecture. These modules work together to surface patterns, score outputs consistently, and drive actionable model improvements.
Insights Engine Module
Surfaces model patterns for PM and Research. Predicts regressions, supports decision-making, and highlights shifts in model behavior.
Adoption and Training
Creates evaluator alignment across teams. Reinforces shared rubric criteria, builds pattern-recognition skills, and ensures consistent application of the QA system.
Signals Map
Defines how we evaluate model quality. Creates consistent failure modes and a shared language across teams.
Evaluation Loop
Turns outputs into actionable insight through scenario suites, weekly pattern detection, and consistent root-cause mapping.
Impact
The QA program changed how teams shipped, measured, and improved AI features.
For Product
• Stronger grounding in long-context tasks due to clearer signal criteria • Faster regression detection through weekly pattern surfaces • Reduced safety drift in sensitive flows from structured failure-mode tagging
For the Org
• A shared quality language across Support, PM, Design, and Research • Faster decisions driven by pattern-based insights instead of anecdotal reports • Predictable evaluation cadence that shifted teams from reactive debugging to proactive governance • Clearer prioritization for Engineering based on tagged failure clusters
For Customers
• Noticeably fewer misleading or incorrect responses in guided steps • More reliable multi-step assistance due to improved grounding • Smoother, more consistent experiences across surfaces as drift was identified earlier
Why This Matters
The QA program created a reliable foundation for how Figma evaluates AI behavior. It gave Support, Product, and Engineering a shared framework for understanding quality, surfaced model patterns that influenced roadmap decisions, and established an evaluation rhythm the teams could depend on.
By replacing anecdotal feedback with structured evidence, the system made it easier to spot regressions, prioritize improvements, and measure progress over time. It also established a repeatable evaluation approach that can be applied to any feature or model.
The methods behind this program draw on systems I’d been developing long before Figma, and they continue to shape how I design quality frameworks in new environments.
From Talk to Practice

These slides walk through the architecture and methods behind this QA program. I presented them at a conference session focused on practical AI evaluation.
See the full deck
Case Study
Building Figma’s First LLM QA Program
A system that detects model failures, protects customer trust, and teaches the organization how to evaluate AI with rigor.
Summary
Figma needed a consistent way to evaluate AI quality across Support. I built a structured QA program that identifies where a model succeeds, where it fails, and why. The system gave teams a shared language for diagnosing issues, measuring improvements, and guiding Engineering toward actionable fixes. The framework draws on systems I’d been developing long before Figma.
Problem
AI was becoming a core part of Figma’s support ecosystem, but there was no reliable way to measure or diagnose quality. Output varied, and teams didn’t have a shared framework for understanding what the model was doing or where it was failing.
Key gaps: • No shared quality rubric • No taxonomy for failure modes • No process for identifying regressions • No durable record of experiments • Specialists didn’t trust outputs • Engineering had no actionable feedback loop
Without a formal evaluation system, quality stayed anecdotal and unmeasurable. The team couldn’t measure performance, pinpoint issues, or provide Engineering with clear signals for improvement.
Approach
I began by mapping the different ways the model could fail. Errors weren’t uniform, so understanding failure types was the fastest way to see where the model needed support. I treated mistakes as a spectrum, from intent and grounding issues to reasoning gaps and policy drift.
I anchored the work around three questions: • Was the intent correct • Was the response grounded in the right information • Did the output align with product and policy expectations
With those patterns defined, I designed a workflow that evaluates responses through these layers in a consistent sequence. The goal wasn’t just to score correctness. It was to create a repeatable method that reveals why the model behaved a certain way and what the right team could act on next.
This replaced pass-fail scoring with a clearer picture of model behavior. Each stage feeds into the next, creating a profile that helps teams debug issues accurately instead of guessing where the problem lies.
The System I Built
This system creates a consistent, repeatable way to understand model behavior across layers, from intent to calibration.
To replace anecdotal evaluation with measurable quality, I designed a modular LLM QA system that combined signals-based scoring, structured failure detection, and a repeatable human-in-the-loop workflow. Each component was built to scale across teams while reducing cognitive load for specialists and giving Engineering actionable feedback.
The QA Modules
These are the core modules that form the system’s architecture. These modules work together to surface patterns, score outputs consistently, and drive actionable model improvements.
Insights Engine Module
Surfaces model patterns for PM and Research. Predicts regressions, supports decision-making, and highlights shifts in model behavior.
Adoption and Training
Creates evaluator alignment across teams. Reinforces shared rubric criteria, builds pattern-recognition skills, and ensures consistent application of the QA system.
Signals Map
Defines how we evaluate model quality. Creates consistent failure modes and a shared language across teams.
Evaluation Loop
Turns outputs into actionable insight through scenario suites, weekly pattern detection, and consistent root-cause mapping.
Impact
The QA program changed how teams shipped, measured, and improved AI features.
For Product
• Stronger grounding in long-context tasks due to clearer signal criteria • Faster regression detection through weekly pattern surfaces • Reduced safety drift in sensitive flows from structured failure-mode tagging
For the Org
• A shared quality language across Support, PM, Design, and Research • Faster decisions driven by pattern-based insights instead of anecdotal reports • Predictable evaluation cadence that shifted teams from reactive debugging to proactive governance • Clearer prioritization for Engineering based on tagged failure clusters
For Customers
• Noticeably fewer misleading or incorrect responses in guided steps • More reliable multi-step assistance due to improved grounding • Smoother, more consistent experiences across surfaces as drift was identified earlier
Why This Matters
The QA program created a reliable foundation for how Figma evaluates AI behavior. It gave Support, Product, and Engineering a shared framework for understanding quality, surfaced model patterns that influenced roadmap decisions, and established an evaluation rhythm the teams could depend on.
By replacing anecdotal feedback with structured evidence, the system made it easier to spot regressions, prioritize improvements, and measure progress over time. It also established a repeatable evaluation approach that can be applied to any feature or model.
The methods behind this program draw on systems I’d been developing long before Figma, and they continue to shape how I design quality frameworks in new environments.
From Talk to Practice
These slides walk through the architecture and methods behind this QA program. I presented them at a conference session focused on practical AI evaluation.
See the full deck
Case Study
Building Figma’s First LLM QA Program
A system that detects model failures, protects customer trust, and teaches the organization how to evaluate AI with rigor.
Summary
Figma needed a consistent way to evaluate AI quality across Support. I built a structured QA program that identifies where a model succeeds, where it fails, and why. The system gave teams a shared language for diagnosing issues, measuring improvements, and guiding Engineering toward actionable fixes. The framework draws on systems I’d been developing long before Figma.
Problem
AI was becoming a core part of Figma’s support ecosystem, but there was no reliable way to measure or diagnose quality. Output varied, and teams didn’t have a shared framework for understanding what the model was doing or where it was failing.
Key gaps: • No shared quality rubric • No taxonomy for failure modes • No process for identifying regressions • No durable record of experiments • Specialists didn’t trust outputs • Engineering had no actionable feedback loop
Without a formal evaluation system, quality stayed anecdotal and unmeasurable. The team couldn’t measure performance, pinpoint issues, or provide Engineering with clear signals for improvement.
Approach
I began by mapping the different ways the model could fail. Errors weren’t uniform, so understanding failure types was the fastest way to see where the model needed support. I treated mistakes as a spectrum, from intent and grounding issues to reasoning gaps and policy drift.
I anchored the work around three questions: • Was the intent correct • Was the response grounded in the right information • Did the output align with product and policy expectations
With those patterns defined, I designed a workflow that evaluates responses through these layers in a consistent sequence. The goal wasn’t just to score correctness. It was to create a repeatable method that reveals why the model behaved a certain way and what the right team could act on next.
This replaced pass-fail scoring with a clearer picture of model behavior. Each stage feeds into the next, creating a profile that helps teams debug issues accurately instead of guessing where the problem lies.
The System I Built
This system creates a consistent, repeatable way to understand model behavior across layers, from intent to calibration.
To replace anecdotal evaluation with measurable quality, I designed a modular LLM QA system that combined signals-based scoring, structured failure detection, and a repeatable human-in-the-loop workflow. Each component was built to scale across teams while reducing cognitive load for specialists and giving Engineering actionable feedback.
The QA Modules
These are the core modules that form the system’s architecture. These modules work together to surface patterns, score outputs consistently, and drive actionable model improvements.
Insights Engine Module
Surfaces model patterns for PM and Research. Predicts regressions, supports decision-making, and highlights shifts in model behavior.
Adoption and Training
Creates evaluator alignment across teams. Reinforces shared rubric criteria, builds pattern-recognition skills, and ensures consistent application of the QA system.
Signals Map
Defines how we evaluate model quality. Creates consistent failure modes and a shared language across teams.
Evaluation Loop
Turns outputs into actionable insight through scenario suites, weekly pattern detection, and consistent root-cause mapping.
Impact
The QA program changed how teams shipped, measured, and improved AI features.
For Product
• Stronger grounding in long-context tasks due to clearer signal criteria • Faster regression detection through weekly pattern surfaces • Reduced safety drift in sensitive flows from structured failure-mode tagging
For the Org
• A shared quality language across Support, PM, Design, and Research • Faster decisions driven by pattern-based insights instead of anecdotal reports • Predictable evaluation cadence that shifted teams from reactive debugging to proactive governance • Clearer prioritization for Engineering based on tagged failure clusters
For Customers
• Noticeably fewer misleading or incorrect responses in guided steps • More reliable multi-step assistance due to improved grounding • Smoother, more consistent experiences across surfaces as drift was identified earlier
Why This Matters
The QA program created a reliable foundation for how Figma evaluates AI behavior. It gave Support, Product, and Engineering a shared framework for understanding quality, surfaced model patterns that influenced roadmap decisions, and established an evaluation rhythm the teams could depend on.
By replacing anecdotal feedback with structured evidence, the system made it easier to spot regressions, prioritize improvements, and measure progress over time. It also established a repeatable evaluation approach that can be applied to any feature or model.
The methods behind this program draw on systems I’d been developing long before Figma, and they continue to shape how I design quality frameworks in new environments.
From Talk to Practice
These slides walk through the architecture and methods behind this QA program. I presented them at a conference session focused on practical AI evaluation.
See the full deck